List 의 종류 (3가지)
- ArrayList
- LinkedList
- Single LinkedList
- Double LinkedList
Single LinkedList
Single LinkedList 를 보통 일반적인 LinkedList라고 부른다.
LinkedList는 데이터가 따로 떨어져 저장되고, 1개의 저장공간 안에서 연속을 유지하기 위해 그다음 공간의 주소를 가지고 있게 된다.

위의 그림에서 파란 네모 공간을 링크드 리스트에서는 Node 라고 한다.
Node는

- 데이터 공간 (오른쪽 상자)
- Next Node Point : 다음 연결 지점, 그다음 공간의 주소를 가지고 있음 (왼쪽 상자)
그림을 통한 이해
아래의 그림은 4개의 Node를 가지는 LinkedList 이다.

맨앞의 Node : Head
맨끝의 Node : Tail (Tail 의 Next Node Point = null 이 설정 되어 있다.)
Single LinkedList 의 시간복잡도
검색
랜덤엑세스 불가능. LInkedList의 index는 List의 순차번호로만 사용됨.
List에 N개의 데이터가 있다면, N번 만큼 순차적으로 이동해야 함 = O(N)

추가
LInkedList 의 끝에 데이터를 삽입
리스트의 끝까지 N번 만큼 순차적으로 이동한 후에 데이터를 추가 = O(N)

삽입
데이터 중간 삽입.
데이터를 추가하고자 하는 위치까지 N만큼 이동해야 함 = O(N)
이동 후에, Tail 의 Next Node Point 들을 이어지게 설정해준다.
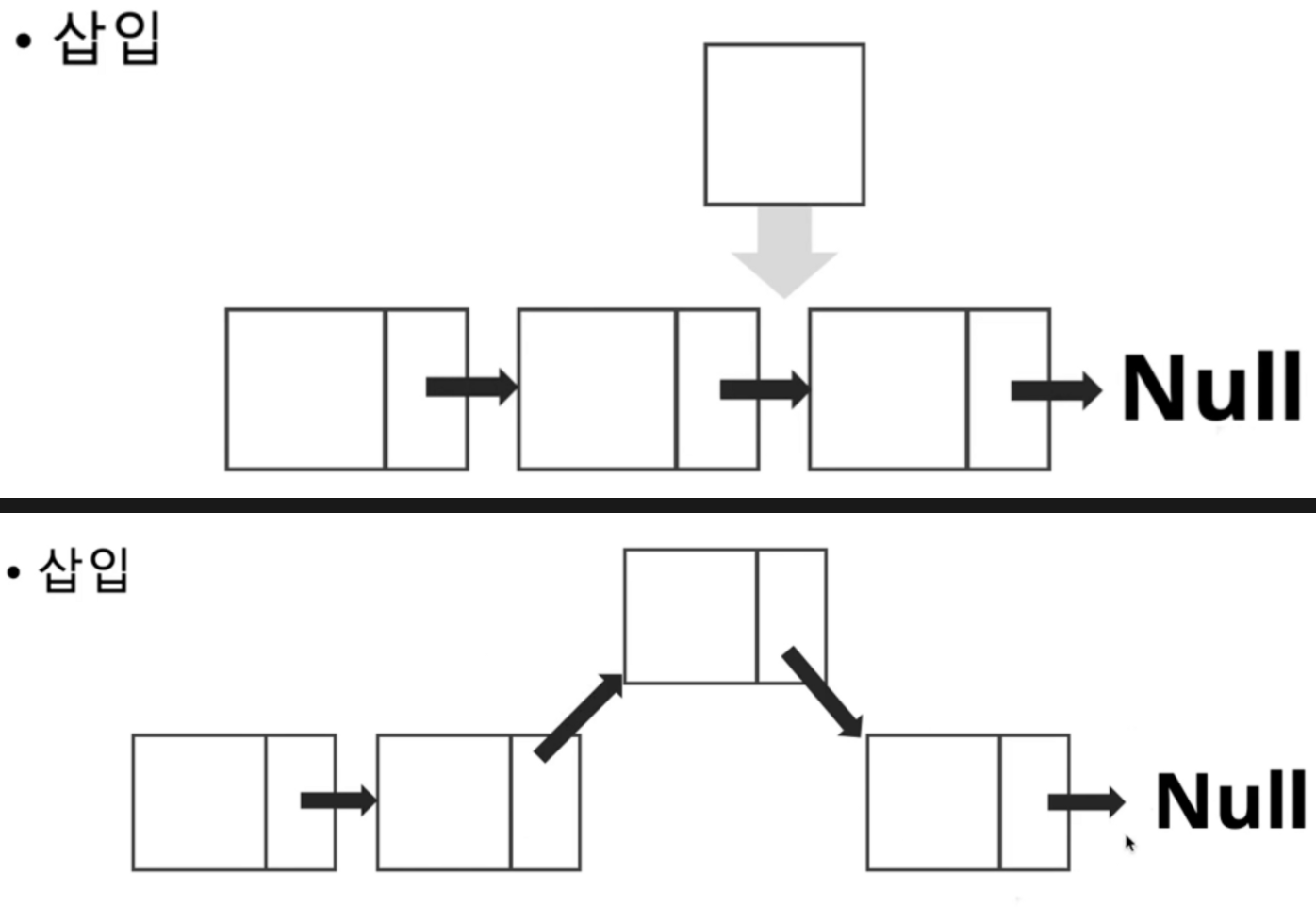
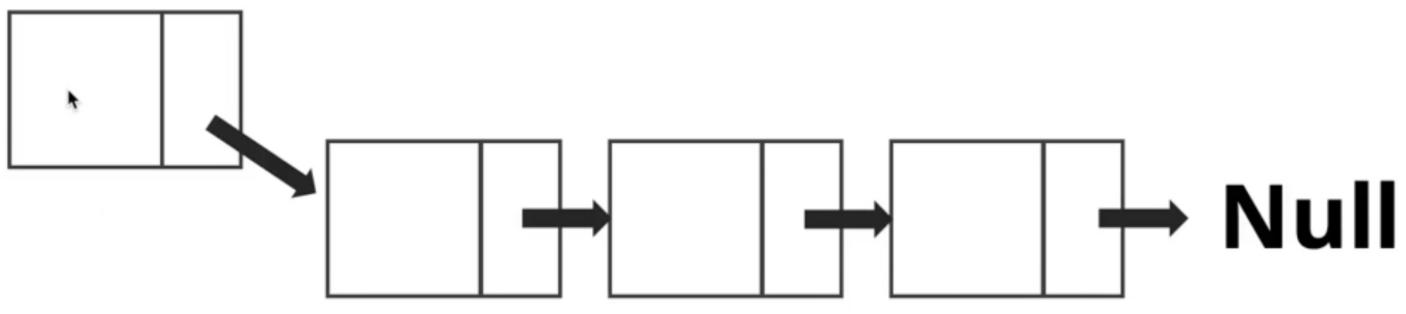
- Head 삽입 (Head 에만 데이터 삽입이 필요한 경우)
ArrayList 에서 [0]번째 인덱스에 데이터를 insert 하면, 매번 뒤로 1칸씩 데이터를 뒤로 미는 O(N) 연산필요.
LinkedList에서는 데이터 밀어냄 필요없음. O(1) 시간복잡도로 맨 앞에 데이터 추가하고, Next Node Point 만 연결
삭제
삭제 또한 삭제하고자 하는 위치까지 N만큼 이동해야 함 = O(N)
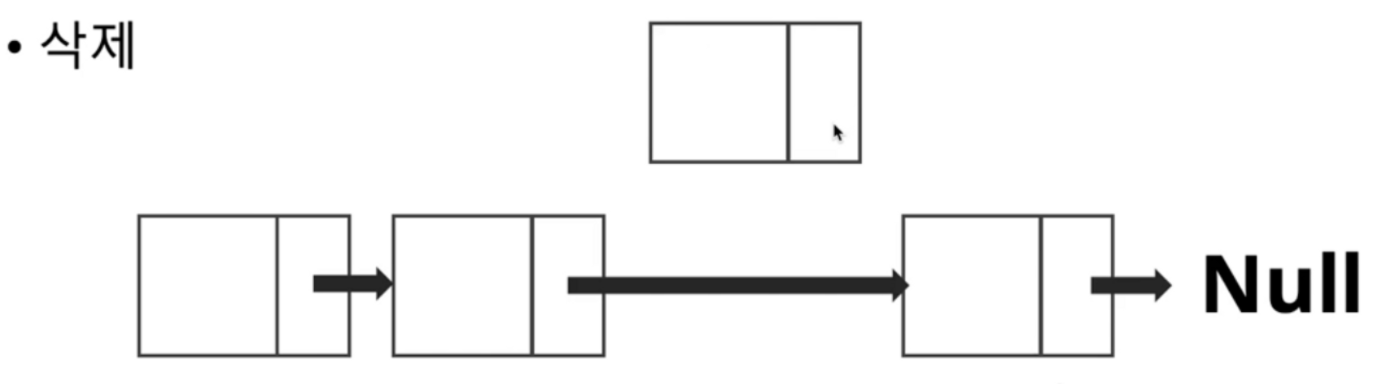
Java 의 경우, 위의 List에서 삭제된 데이터는 해당 데이터가 일정 횟수 이상 참조 되지 않았을 경우 GC 에 의해 수거 되어 영구 삭제 된다.(GC 에서 더이상 사용되지 않는 데이터라고 판단한다.)
LinkedList 는 랜덤엑세스가 아닌 순차접근이므로 어떤 경우이든 간에 해당 위치까지 O(N) 만큼 찾아가야 한다.
get(index) : 인덱스를 통한 검색 : O(N)
⇒ 원하는 index가 나올때 까지, Head에서 출발해 N번에 걸쳐 Node를 이동
insert(index, T) : 중간삽입 : O(N)
⇒ 중간에 삽입될 직전 노드까지, N번에 걸쳐 Node를 이동
add : 맨끝에 데이터 추가 : O(N)
⇒ 마지막 노드까지, N번에 걸쳐 Node를 이동
delete by value: 중간삭제 [값] : O(N)
⇒ 삭제될 노드까지, N번에 걸쳐 Node를 이동
delete by index : 중간삭제 [index] : O(N)
⇒ 삭제될 노드까지, N번에 걸쳐 Node를 이동
장점
- LinkedList 에서는 O(N)만큼 찾아가서, NextPointer 를 변경 해주기만 하면된다. (ArrayList 보다는 삽입,삭제에 유리하다 )
⇒ ArrayList의 경우 꽉찼을때, 안에 데이터를 다 비우고, 더 큰 size의 새로운 ArrayList를 생성하여, 데이터를 다시 재배치 하는 과정들을 거친다.
- 유연한 공간 활용
⇒ ArrayList는 마치 테트리스의 가로4줄과 같다. 잘못 할당하면, 공간 낭비 심각하다.
⇒ 하지만, LinkedList 는 1개씩 데이터들을 연결처리 함으로, 효율적으로 메모리 공간 사용가능.
단점
- 순차적으로 접근해야하기 때문에 읽기 속도가 ArrayList 보다 느리다.
'자료구조' 카테고리의 다른 글
| Queue(선형 큐) (0) | 2022.12.11 |
|---|---|
| Stack (0) | 2022.12.11 |
| Double LinkedList (0) | 2022.12.11 |
| ArrayList (0) | 2022.12.10 |
| Array (0) | 2022.12.10 |



